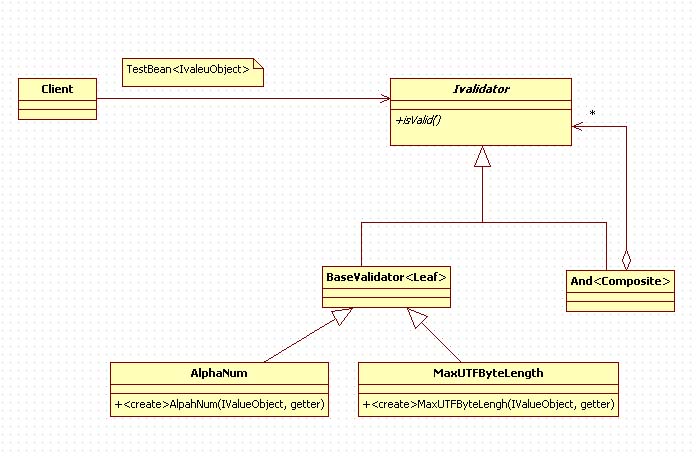
Framework를 작성할때 가장 먼저 생각해야 하는것은 실험실과 비실험실의 분류이다. 실험실이란 일종의 무균의 연구실을 상상하면 된다. 이 곳에서는 이 코드가 실제 사용될 비실험실의 제약에 대해 전혀 고려하지 않는다는게 포인트다. 오직 코드의 효율 그 자체만을 추구하며 공학이 가지는 모든 특성을 무시해도 상관없고 오히려 의도적으로 무시되어야 한다.
실험실의 코드는 오직 코드의 1차 목적에만 집중하는데 일차적으로 코드의 효율성이나 디자인의 간결함만을 추구해야 한다. 실험실의 코드는 비실험실에 대해 의도적으로 무시하기 때문에 비 실험실은 실험실 코드에 대해 최소한의 정보만 알기 때문에 request와 response 모두 인터페이스 기반 통신을 하게된다.
말은 조금 어려워졌지만 사실 유효성 검사와 관련한 실험실 코드를 작성하는 것은 그닥 어려운 일이 아니다.
첫째 고려해야 할 것은 유효성검사가 필요한 객체타입은 - 아마도 대부분 Getter 함수를 가지고 있는 Bean 형태의 객체가 되겠지만 - 비실험실에서 어떻게 사용될지 모르는 실험실 코드에서는 제약할수 없기 때문에 Object 형태가 되어야 한다. 다만 그냥 Object는 좀 그러니까 Serializable 인터페이스같이 메소드 정의가 없는 IValueObject 인터페이스를 사용하기로 하자.
public interface IValueObject {
}
public class TestBean implements IValueObject {
private int ivalue;
private String svalue;
public int getIvalue() {
return ivalue;
}
public void setIvalue(int ivalue) {
this.ivalue = ivalue;
}
public String getSvalue() {
return svalue;
}
public void setSvalue(String svalue) {
this.svalue = svalue;
}
}
와 같은 TestBean을 만든다. 비실험실에서 실험실 코드로 IValueObject 를 던지면 실험실 코드의 response도 하나의 interface가 될수도 있겠지만 사실 boolean isValid() 말고는 그닥 특별한 정보가 필요가 없다. 말했다시피 실험실은 외부와 차단되어 있어야 하기 때문에 최소한의 정보만을 주고받는다.
따라서 실험의 모든 유효성 검사 객체는 아래 인터페이스를 구현하게 된다.
public interface IValidator {
public boolean isValid() ;
}
예를 들어 공백이어서는 안된다라는 유효성은
public class Required extends BaseValidator{
public Required(IValueObject valueObject, String name) {
super(valueObject, name);
}
public boolean isValid() {
Object value = invokeGetter() ; // reflection
if (value == null) return false ;
return StringUtil.isNotBlank(value.toString()) ;
}
}
와 같이 작성될 것이다.
테스트 코드는 아래와 같이 작성된다.
public class StandardValidationTest extends TestCase{
private TestBean b = new TestBean() ;
private String SVALUE = "svalue";
public void setUp(){
b = new TestBean() ;
}
public void testRequired() throws Exception {
assertEquals(false, new Required(b, SVALUE).isValid());
b.setSvalue("") ;
assertEquals(false, new Required(b, SVALUE).isValid());
b.setSvalue(" \t\n") ;
assertEquals(false, new Required(b, SVALUE).isValid());
b.setSvalue("a") ;
assertEquals(true, new Required(b, SVALUE).isValid());
}
}
이런식으로 실험실 코드를 작성하면 된다. 사실 실험실 코드를 작성하는 것은 아주 쉬운일이다. 제약과 예외가 거의 없기 때문이다. 그리고 물론 제약과 예외를 고려하지 않는 것은 의도적인 것이다. 제약과 예외는 비실험실에서 생기는 것이며 그곳의 문제를 결코 실험실안으로 끌고 들어와서는 안된다.
이제 온갖 세균과 예외와 제한이 있는 비실험실인 현실세계로 돌아와 보자.
앞서 말했듯이 실제 어려운 것은 현실세계의 접촉 지점이다.
1. 프로그램에서 직접 호출하는 방법
모든 프레임워크가 그런것은 아니지만 유효성검사 프레임워크는 프로그램에서 직접 호출방식은 거의 고려할 필요가 없다. 왜냐하면 유효성 검사라는 말 자체가 가지는 개별적인 비지니스 특징때문이다. 어떤 객체의 유효성이란 거의 항상 비지니스 도메인에서 개별적으로 정해지기 마련이고 이는 다시 말해서 굉장히 유연해야 하므로 컴파일이 되는 딱딱한 바이트 코드에 넣어서 관리하는 것은 의미가 없다.
2. XML 설정 파일을 이용하는 방법
사실 대부분의 구성 정보는 XML을 통해 관리하는게 정답이긴 하다. 이전의 Property 파일보다는 다 짜임새 있기 때문이다. 다만 XML 파일은 앞서 말한대로 효과에 비해 지나치게 복잡하다. 정도의 문제이긴 하지만 일반 구성 정보가 아닌 수십 - 수백개에 이르는 개체의 대한 유효성 정보를 XML파일로 관리하는 것은 쉬운 일이 아니다. 게다가 유효성 검사의 특성상 많은 중복 정보가 발생하는데 - 이를테면 Required 가 필요한 수는 객체수 * 프로퍼티 * 0.3 정도이다. - 이를 효과적으로 처리하는게 어렵다.
두번째로 접착성이 떨어지는데 여기서 접착성이란 비지니스 프레임워크와 너무 단단하게 연결되어 있기 때문에 프레임워크의 이전이 쉽지 않다는 문제도 있다. 사실 현재의 Struts와 Spring의 Validation Code의 가장 큰 문제가 이거다. 더군다나 편의를 위한다고 써먹지도 못하는 듣보잡 자바스크립트 코드를 지멋대로 생성하곤 한다. - 이딴걸 어따 쓰라고 -ㅅ-; 프레임워크는 어디에도 붙일수 있는 포스트 잇의 접착도를 가져야 하지 일단 붙으면 떨어지기 힘든 본드의 접착도를 가져서는 안된다.
XML파일로 관리했을때 세번째 문제는 복잡한 유효성 감사를 다루기가 어렵다는 데 있다. 물론 그에 해당하는 CustomBean을 만들어서 어떻게 해결할 수도 있겠지만 케이스 바이 케이스로 하나씩 만든다는 것은 지나친 수고로움을 유발한다.
그럼 어떻게 해야할까? 보통 다른 선택이 있다면 Rule Engine를 제작하는 방법이 있다. Rule 엔진은 간단한 정의와 프로세싱 기능이 있기 때문에 XML파일보다는 훨씬 유연하고 자유롭다. 다만 일반적으로 Rule Engine은 보편성을 갖기가 힘들기 때문에 유효성 검사의 경우에 한정한다면 배보다 배꼽이 커지는 경우라 할 수 있다.
그래서 가장 그럴듯한 다른 방법은 자바에 내장되어 있는 Rhino 같은 스크립트 엔진을 활용하는 것이다.
장점은 아래와 같다.
첫째 스크립트의 유효성 검사 코드 대부분을 재활용할 수 있다.
둘째 스크립트는 XML 보다 훨씬 더 익숙하다.
셋째 스크립트는 로직을 가질 수 있다.
넷째 XML 에 비해 불필요한 중복을 줄일수 있다.
다섯째 스크립트는 순수 텍스트인 XML에 비해 자체적으로 테스트가 가능하다.
가장 큰 장점은 첫째와 셋째이다.
기존의 브라우저에서 사용되는 자바 스크립트를 사용할 수도 있고 펄이나 파이썬이 익숙하다면 그것도 상관이 없다.
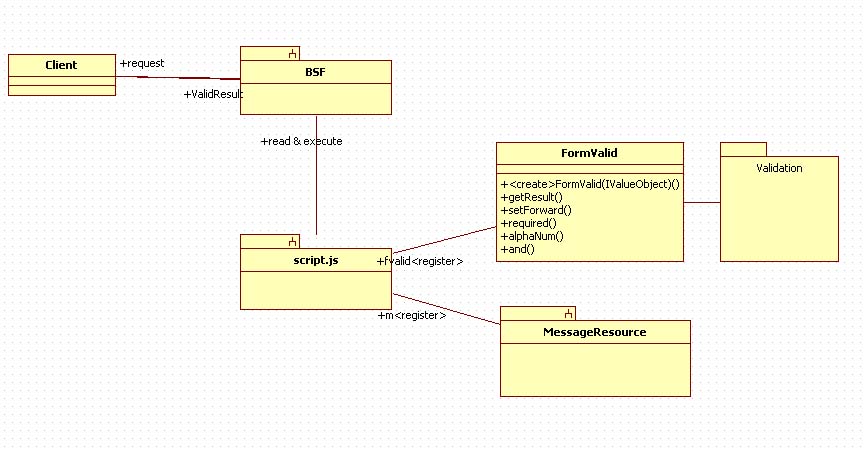
script.js 파일은 기존의 자바 스크립트에서 복사해서
<script.js>
fvalid = bsf.lookupBean ("fvalid");
m = bsf.lookupBean("m");
fvalid.setForward("add") ;
fvalid.required("subject", m.get("jmsg.validate_null", m.get("etc.subject")), true);
fvalid.maxLengthByte("subject", 200, m.get("jmsg.length", m.get("etc.subject"), "1", "200"), true);
// fvalid.notAllowed2ByteSpace("subject", m.get("jmsg.include_fullwidth_space", m.get("etc.subject")), true);
fvalid.required("content", m.get("jmsg.validate_null", m.get("etc.cont")), true);
......
와 같이 저장한다.
실제 코드에서는 위와 같이 저장된 js 파일을 읽어서 실행하게 된다.
이를 테스트 할수 있는 코드는 아래와 같다.
package test.bsf;
import java.io.FileReader;
import junit.framework.TestCase;
import org.apache.bsf.BSFManager;
import org.apache.bsf.util.IOUtils;
import com.bleujin.framework.res.Resources;
public class TestFormValid extends TestCase {
private BSFManager mgr = new BSFManager();
TestContentBean bean ;
private FormValid fvalid ;
private Resources m ;
public void setUp() throws Exception{
bean = new TestContentBean() ;
fvalid = new FormValid(bean) ;
m = Resources.getResources("default") ;
mgr.registerBean("fvalid", fvalid) ;
mgr.registerBean("m", m) ;
}
public void testFalse() throws Exception {
FormValid fvalid = runScript("D:\\eclipse\\workspace\\testAnother\\src\\vtest.js", "add");
assertEquals(false, fvalid.getResult("add").isValid()) ;
}
public void testTrue() throws Exception {
FormValid fvalid = runScript("D:\\eclipse\\workspace\\testAnother\\src\\vtest.js", "add");
assertEquals(true, fvalid.getResult("").isValid()) ;
bean.setSubject("abcd") ;
bean.setContent("defg") ;
assertEquals(true, fvalid.getResult("add").isValid()) ;
}
private FormValid runScript(String fileName, String forwardName) throws Exception{
String language = BSFManager.getLangFromFilename(fileName); // get scripting language name
FileReader in = new FileReader(fileName);
String script = IOUtils.getStringFromReader(in); // read script from file
mgr.exec(language, fileName, -1, -1, script); // execute scriptusing appropriate engine*
return fvalid ;
}
} |
FormValid 객체는 기존의 자바 스크립트 코드를 흉내내어 만든 Java 객체이다.
대충 이런 형태이다.
package test.bsf;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.bleujin.framework.valid.IValueObject;
import com.bleujin.framework.valid.validator.MaxUTFByteLength;
import com.bleujin.framework.valid.validator.Required;
import com.bleujin.framework.valid.validator.IValidation;
public class FormValid {
private Map<String, List<ValidRule>> rules = new HashMap<String, List<ValidRule>>();
private String currentForwardName = "";
private IValueObject valueObject ;
public FormValid(IValueObject valueObject){
this.valueObject = valueObject ;
setForward("") ;
}
public void setForward(String forwardName){
this.currentForwardName = forwardName ;
rules.put(forwardName, new ArrayList<ValidRule>()) ;
}
public void required(String name, String errorMessage, boolean focus) {
getCurrentSet().add(new ValidRule(new Required(valueObject, name), errorMessage, focus)) ;
}
public void maxLengthByte(String name, int maxByte, String errorMessage, boolean focus){
getCurrentSet().add(new ValidRule(new MaxUTFByteLength(valueObject, name, maxByte), errorMessage, focus)) ;
}
public ValidResult getResult(String forwardName){
List<ValidRule> currentRules = rules.get(forwardName) ;
ValidResult result = new ValidResult();
for(ValidRule rule : currentRules){
if (! rule.getValidator().isValid()){
result.addInvalidRule(rule) ;
}
}
return result ;
}
private List<ValidRule> getCurrentSet(){
return rules.get(currentForwardName);
}
}
class ValidResult {
List<ValidRule> lists = new ArrayList<ValidRule>() ;
void addInvalidRule(ValidRule rule){
lists.add(rule) ;
}
public boolean isValid(){
return lists.size() == 0 ;
}
public String getErrorMessage(){
StringBuffer result = new StringBuffer() ;
for(ValidRule rule : lists) {
result.append(rule.getErrorMessage() + "\n") ;
}
return result.toString() ;
}
}
class ValidRule{
private IValidation validator ;
private String errorMessage ;
private boolean focus ;
ValidRule(IValidation validator, String errorMessage, boolean focus){
this.validator = validator ;
this.errorMessage = errorMessage ;
this.focus = focus ;
}
public IValidation getValidator() {
return validator;
}
public String getErrorMessage() {
return errorMessage;
}
public boolean isFocus() {
return focus;
}
}
|


 framework.jar
framework.jar framework_src.zip
framework_src.zip